이클립스 문서 번역 사이트(노트)
퍼온곳: http://silent.springnote.com/pages/98847
출처 : http://www.eclipse.org/articles/Article-TPTP-Profiling-Tool/tptpProfilingArticle.html
설치를 간편하게 하기 위해선 기존 eclipse 는 그대로 두고 아래 올인원 패키지를 다운받으시는걸 추천
http://www.eclipse.org/tptp/home/downloads/
Copyright © 2006 International Business Machines Corp.

TPTP 를 이용한 자바 어플리케이션 프로파일링
요약
이클립스 테스트 & 성능 툴 플랫폼 (TPTP) 프로파일링 툴은 이클립스 플러그인을 프로파일하기 위해 사용할 수 있다. 로컬 자바 어플리케이션은 물론 여러 개의 호스트나 서로 다른 플랫폼에서 동작하는 복잡한 어플리케이션에도 가능하다. 이 툴은 이클립스에 통합되어 있으며, 이클립스 상에서 동작하는 어플리케이션의 프로파일링을 해준다.
이 문서는 TPTP 프로파일링 툴을 가지고 문제가 있는 동작을 확인하기 위해 자바 어플리케이션을 프로파일 하는 방법을 설명한다. 프로파일 세션을 시작하는 방법, 데이터 분석을 위한 다양한 TPTP 뷰를 사용하는 방법, 실행 시간이 긴 메소드를 확인하여 성능 문제를 해결하기 위해 소스 코드로 이동하는 것까지 보여준다.
By Valentina Popescu, IBM
February 21, 2006 (updated July 11, 2006)
번역 : 이상훈(calm1979@gmail.com)
2007년 4월 7일
어플리케이션 프로파일링
지금처럼 제품을 만들어 내기 위한 단기적인 개발 사이클을 돌고 있는 상황에서는, 개발자들이 테스트, 디버깅, 코드 수정을 통한 함수의 기능적인 측면에만 중점을 두는 경향이 있다. 그러나, 대다수의 문제는 어플리케이션이 (하루 24시간, 일주일에 7일 그리고 예상치 못한 피크 타임에의 한계까지 도달하게 되는) 실제 제품으로 동작할 때까지 쉽게 드러나지 않는다.
이런 류의 성능 문제는 디버깅 단계에서는 볼 수 없는 것들이다. 제품을 배포하기 전에 실제 상황에서 돌려보는 것이 중요하다. 어플리케이션의 동작을 분석하고, 병목현상, 객체 누수, 시스템 자원 제한 같은 성능 문제를 찾아내기 위해 프로파일링 툴을 사용하는 것은 중요하다.
이 문서는 TPTP 프로파일링 툴을 소개한다. 그리고, 성능 문제를 확인하고 수정, 검증하기 위해 자바 어플리케이션을 프로파일링 할 수 있도록 TPTP 프로파일링 툴의 사용법을 설명한다.
TPTP 프로파일링 툴
이클립스 테스트 & 성능 툴 플랫폼 (TPTP) 프로젝트는 병목현상, 객체 누수 그리고 시스템 자원 제한 같은 성능 문제를 확인하고 처리할 수 있는 프로파일링 툴을 제공한다. 이 툴은 단순한 독립적인 자바 어플리케이션부터 이클립스 플러그인까지 혹은 서로 다른 플랫폼이나 다양한 머신에서 돌아가는 복잡한 엔터프라이즈 어플리케이션까지 목표로 한다.
이클립스 프로젝트와 완벽하게 통합되어 있기 때문에, 사용하기 쉽고 확장하기도 쉽다. 이것은 사용자가 자신의 데이터 분석 화면을 붙일 수도 있고, 데이터 수집 에이전트에서 자신의 구현을 통해 데이터 수집 메타포어(metaphor)를 확장할 수 있음을 의미한다.
이 문서는 이클립스 3.2.0을 필요로 하는 EMF 2.2.0 과 XSD 2.2.0 을 기반으로 하는 TPTP 4.2.0 을 사용해서 작성했다. 여기에서 이것들을 구할 수 있다. TPTP 4.2.0 설치를 위한 설명을 보려면 TPTP 다운로드 페이지 로 가면된다.
TPTP 를 이용한 자바 어플리케이션 프로파일링
이 문서에서 사용한 제품 카탈로그 샘플 어플리케이션은 각각의 xml 파일에 저장된 제품 정보를 분석해서 콘솔 화면에 결과를 출력하는 간단한 자바 어플리케이션이다. 제품 정보를 포함하는 xml 파일들이 위치한 디렉토리 경로는 Product.java 프로그램의 인자로 주어진다. 제품 정보를 포함하고 있는 xml 파일들은 예제 실행하기에서 제공한다.
프로파일링 모드로 어플리케이션 시작하기
샘플 어플리케이션을 설치한 후에, 첫 단계로 제품 카탈로그 어플리케이션을 프로파일링 모드로 실행한다. 아래 그림 1처럼 Product.java 를 선택하고 팝업 메뉴의 Profile As > Java Application 를 선택해서 어플리케이션을 프로파일한다.
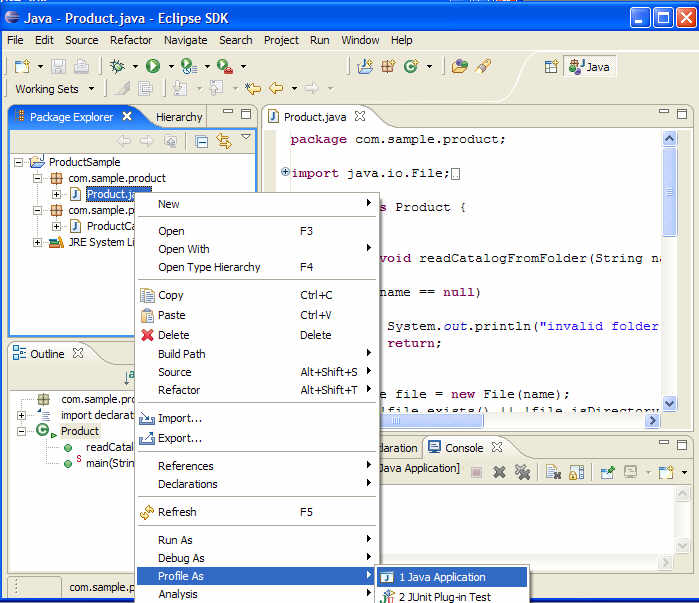
그림 1 제품 카탈로그 어플리케이션 프로파일 하기
 프로파일링 모드로 어플리케이션을 실행하는 다른 방법은 자바 퍼스펙티브의 툴바 메뉴에 있는 Profile 액션을 사용하는 것이다. Run 이나 Debug 툴바 액션 처럼, Profile 액션은 런치 설정(launch configuration) 다이얼로그를 나타낼 것이다. 다이얼로그에서 프로파일 하고 싶은 어플리케이션의 타입을 선택할 수 있다.
프로파일링 모드로 어플리케이션을 실행하는 다른 방법은 자바 퍼스펙티브의 툴바 메뉴에 있는 Profile 액션을 사용하는 것이다. Run 이나 Debug 툴바 액션 처럼, Profile 액션은 런치 설정(launch configuration) 다이얼로그를 나타낼 것이다. 다이얼로그에서 프로파일 하고 싶은 어플리케이션의 타입을 선택할 수 있다.
자바 프로그램 인자 설정하기
The Profile As > Java Application 을 선택하면 그림 2와 같은 런치 설정 마법사(Launch Configuration Properties wizard)가 열릴 것이다.
이 예제에서는 제품 xml 파일의 경로를 프로그램의 인자로 넘겨준다. 이 문서의 제일 아래에서 제공되는 파일을 x:\myPath 에 풀었다고 할 경우 x:\myPath\products 를 아래 그림 2에서 보여지는 것처럼 프로그램 인자로 설정한다.
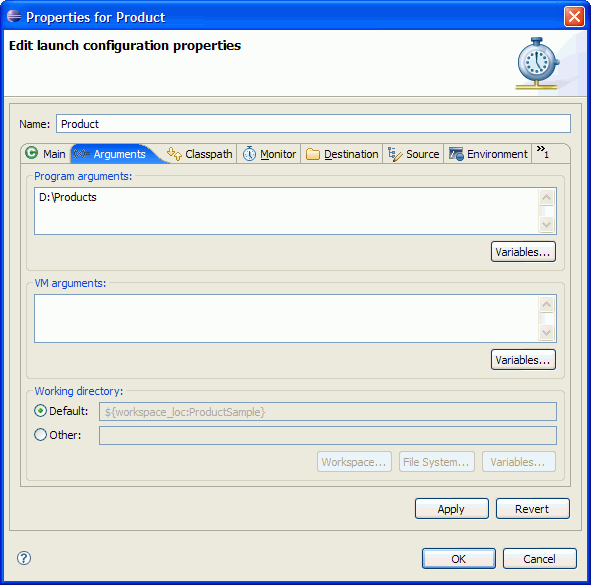
그림 2 제품 카탈로그 샘플 – 프로그램 인자(Program arguments)
프로파일링 필터 설정하기
다음 단계로 메소드 실행 정보를 수집하기 위한 프로파일링 옵션을 설정한다.
이 옵션을 설정하기 위해, 런치 설정 마법사(Launch Configuration Properties wizard)의 모니터(Monitor) 탭을 선택하고, 측정하고자 하는 프로파일링 옵션을 설정한다.
프로파일링 필터 셋(Profiling filter set)은 프로파일링 필터의 재사용 가능한 셋(set)이다. 프로파일링 필터 셋을 만드는 이유는 같은 어플리케이션을 연속적으로 실행하거나, 어플리케이션 간에 같은 종류의 프로파일링 정보를 수집하기 위해 필터 셋을 재사용하기 위함이다.
아래에서 제품 카탈로그 어플리케이션을 프로파일 하기 위해 사용되는 새로운 필터 셋을 만드는 방법을 설명한다. com.sample.product 로 시작하는 패키지에 대해서만 사용하는 ProductFilterSet 이라는 새로운 필터 셋을 만들 것이다.
1. 실행 정보를 수집하기 위해 모니터(Monitor) 탭에서 실행 시간 분석(Execution Time Analysis) 옵션을 선택한다.
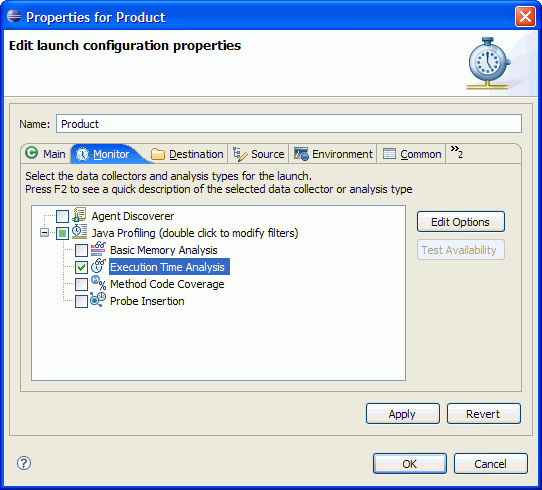
그림 3 실행 시간 분석(Execution Time Analysis) 옵션
위 그림 3에서 보는 바와 같이 실행 시간 분석(Execution Time Analysis) 옵션을 선택했다. 이것은 제품 카탈로그 어플리케이션의 연속적인 실행 중에 사용될 수 있다. 이 어플리케이션의 다음 실행 때에는 “프로파일링 필터 설정하기” 단계는 건너뛸 수 있다.
2. 프로파일링 실행 옵션을 설정하기 위해 “옵션 수정(Edit Options)” 버튼을 누른다.
2a. "Collect boundary classes excluded by the filter set" 옵션을 선택하고 Boundary class depth 값으로 3을 입력한다.
이 옵션을 선택함으로써, 필터 범위 내에서 실행되는 메소드들 중에 입력된 단계(depth)까지 호출되는 메소드에 대한 정보를 수집하겠다고 설정 한 것이다.
예를 들어, MyMethod 라는 메소드에 대해 정보를 수집하도록 설정했고, M1, M2, M3, M4 메소드에 대해 필터 설정을 했다고 하자.
다음과 같은 invocation stack 이 실행되었다고 한다면: MyMethod > M1 > M2 > M3 > M4 ( MyMethod 가 M1 을 호출하고, M1이 M2를 호출하고, M2가 M3를 호출하고, M3가 M4를 호출했다.), 2a 에서 설정한 필터 범위 값에 따라, 프로파일러는 콜 스택을 다음과 같이 보여줄 것이다: MyMethod > M1 > M2 > M3 그리고 마지막 M3>M4는 표시되지 않을 것이다. (호출 단계(depth)가 3을 초과했기 때문이다).
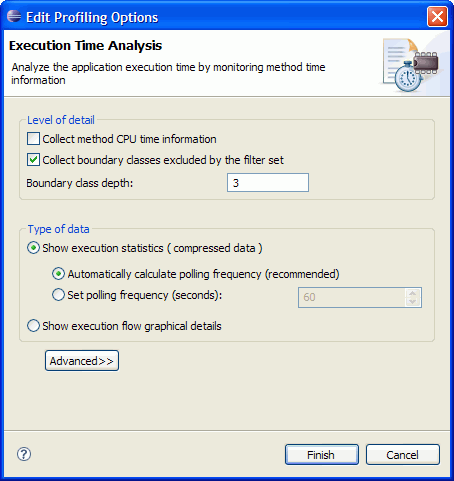
그림 4 실행 정보 수집을 위한 설정
3. 프로파일 하기 위한 클래스들을 선택하기.
모니터(Monitor) 탭에서, 자바 프로파일링(Java Profiling) 아이템을 선택하고 옵션 수정(Edit Options)을 선택한다. 그러면 필터 셋 마법사(Filter Set wizard)가 뜬다.
필터 셋 페이지는 프로파일 하고자 하는 클래스를 선택하기 위해 사용한다. 사용 가능한 필터들이 설정되어 있을 것이다. 그러나 이 예제에서는 com.sample.product 로 시작하지 않는 모든 패키지를 제외하는 ProductFilterSet이라고 하는 새로운 필터 셋을 만들 것이다.
필터 셋을 만들기 위한 단계:
3a) 필터 셋(filter set) 목록에서 추가(Add...) 버튼을 선택한다. 새로운 필터 셋의 이름을 ProductFilterSet 을 입력하고 확인(OK)을 누른다.
3b) 그림 5에서 보는 것 처럼 두 개의 필터를 추가하기 위해 선택된 필터 셋(Contents of selected filter set) 목록에서 추가(Add…) 버튼을 누른다.
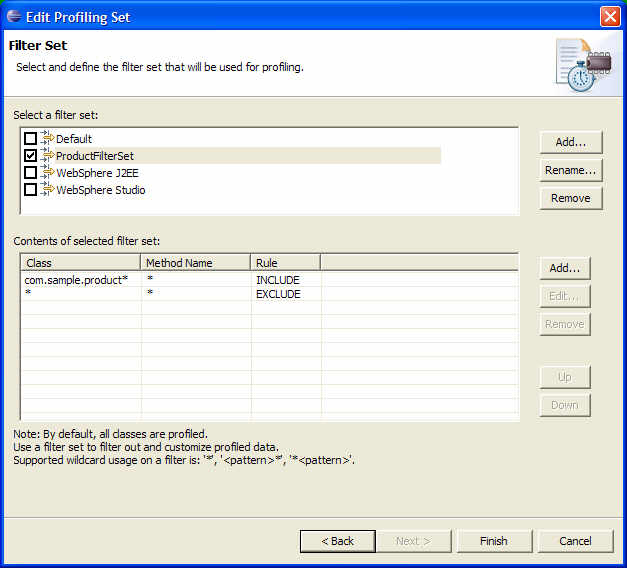
그림 5 프로파일 하고자 하는 클래스 선택하기
어플리케이션 실행하기
런치 설정 마법사(Launch Configuration wizard)에서 확인(OK)을 누름으로써 제품 카탈로그 어플리케이션(Product catalog application)을 실행한다. 프로파일링 & 로깅(Profiling and Logging) 퍼스펙티브로 전환하겠냐는 다이얼로그가 뜨면 예(Yes)를 선택한다.
아래 그림 6에서처럼 콘솔 화면에 프로그램 실행 결과가 출력되는 것을 볼 수 있을 것이다.
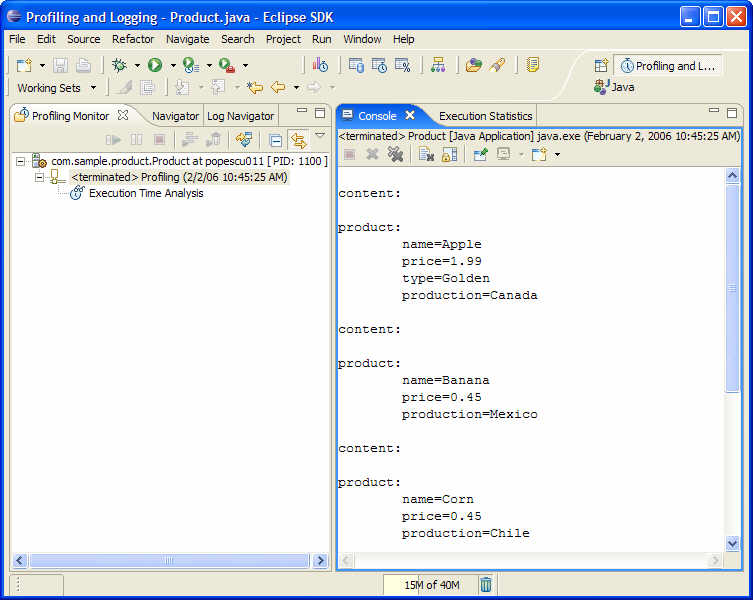
그림 6 제품 카탈로그 어플리케이션(Product catalog application)이 실행되었다
TPTP 프로파일링 툴은 어플리케이션과의 상호 작용을 할 수 있도록 한다. 모니터링을 일시 정지, 다시 시작 할 수 있으며, GC(garbage collection)를 실행할 수도 있고 객체 레퍼런스(object references)를 수집하거나 어플리케이션을 종료할 수도 있다.
실행 통계(Execution Statistics) 뷰를 이용한 성능 문제 확인하기
성능 문제를 확인하기 위해 실행 통계 뷰를 사용한다. 뷰를 열기 위해, 프로파일링 모니터 뷰에서 프로세스(process)를 선택하고 Open with > Execution Statistics 를 선택한다.
아래 그림 7 에서 보는 바와 같이 실행 통계 뷰에서는 실행된 메소드들을 누적 시간(cumulative time)으로 정렬해서 볼 수 있다. 메소드의 누적 시간은 다른 메소드를 호출하는 것을 포함한 실행 시간이다.
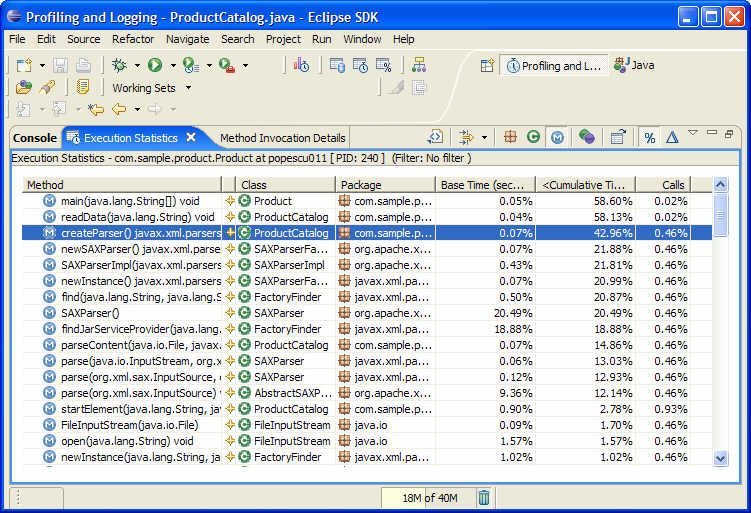
그림 7 실행 통계(Execution Statistics) 뷰
그림 7 을 보면, main(java.lang.String[]), readData(java.lang.String) 그리고 createParser()의 3가지 메소드가 가장 오랜 실행 시간을 사용한 것을 알 수 있다. Main과 readData 메소드가 상위에 있는 것은 걱정할 것이 아니다. 처음 것은 어플리케이션의 시작점이고, 두번째 것은 xml 파일로부터 제품 정보를 읽어들이는 것이기 때문이다.
우리가 지켜봐야할 것은 단지 xml 파일을 파싱(parsing) 하기 위해 SAX 파서 인스턴스를 만드는 creatParser() 메소드가 높은 실행 시간을 나타내고 있다는 것이다. 이 메소드의 실행 시간이 어플리케이션의 전체 실행 시간에 42.96%나 차지한다. 실행 통계는 이 메소드가 어플리케이션의 성능을 최적화하기 위한 가능성이 있는 부분임을 알게 해준다.
일단 이 것을 확인했으면, createParser() 메소드의 상세 실행 정보를 보기 위해 드릴 다운(drill down) 해보자.
createParser() 메소드에서 메소드 호출 상세(Method Invocation Details ) 뷰 열기
다음으로 우리는 createParser() 콜 스텍의 어떤 메소드가 이 메소드의 실행 시간을 느리게 하는지 보기 위해 메소드 호출 상세 뷰를 사용한다. 실행 통계 뷰에서 createParser() 메소드를 더블 클릭하여 메소드 호출 상세 뷰를 열자.
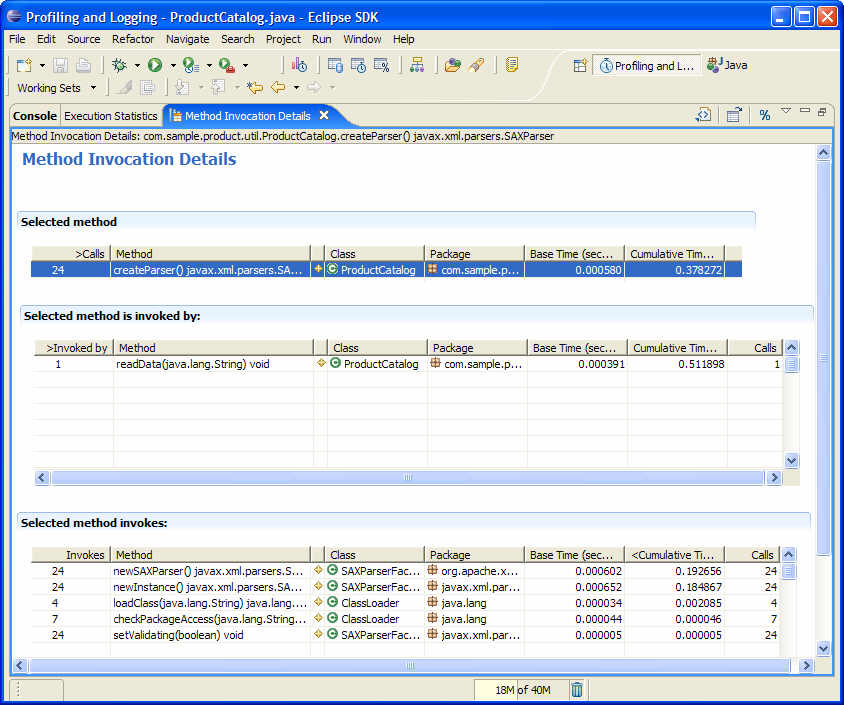
그림 8 메소드 호출 상세(Method Invocation Details) 뷰
그림 8에서는 createParser() 메소드의 실행 정보를 보여준다. 보는 바와 같이 이 메소드는 readData(java.lang.String)에 의해서 한 번 호출되었고 5개의 다른 메소드들을 호출함을 알 수 있다. 호출한 메소드(Selected method invokes) 테이블을 보면 newSAXParser()와 newInstance() 메소드가 createParser() 메소드를 느리게 한다는 것을 알 수 있다. createParser() 메소드가 24번 호출된 것 처럼 이 두 메소드가 24번이나 호출되었다.
확인된 성능 문제로부터 해결책을 정의하기
이 데이터를 분석함으로써, 우리는 createParser() 메소드의 실행 시간 향상을 위해서는 두 개의 SAXParserFactory 메소드의 샐행 향상을 해야한다는 것을 알았다. 우리는 이 메소드의 구현에 관여할 수 없으므로, 우리의 어플리케이션 실행 향상을 위해서는 이 메소들의 호출을 최대한 줄여야한다.
해결책은 모든 파일 마다 새로운 파서를 만들지 않고, 하나의 파서 인스턴스를 만들고 이것을 재사용하는 것이다. 소스 코드를 열고 수정해보자.
이런식의 최적화 방향을 결정하기 전에, 코드 상에서 지원을 하는지를 확실하게 해둘 필요가 있다. 예를 들어, SAXParser는 여러 쓰레드에 의해서 동시에 사용될 수 없기 때문에 인스턴스를 재사용할 수 있는 것이다. 엄격하게 말하면 인스턴스는 재사용하기 전에 reset()해주어야 한다. 변경 내용을 적용할 수 있는 코드를 작성하기 전에 포괄적인 단위 테스트 조합을 구성해두는 것도 좋은 생각이다.
소스 코드를 열고 성능 문제를 수정하기
createParser() 메소드에 대한 소스 코드를 열기 위해 메소드 호출 상세(Method Invocation Details) 뷰에서 마우스 우클릭을 하고 팝업 메뉴에서 소스 열기(Open Source)를 선택한다.
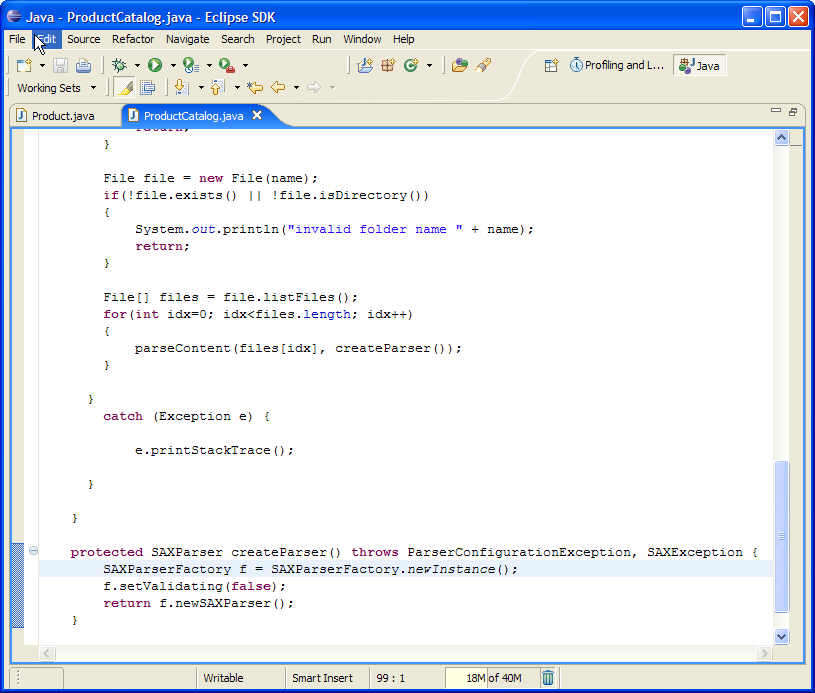
그림 9 소스 코드
그림 9에 createParser() 에 대한 소스 코드가 있다. 이 메소드가 매번 호출될 때 마다 새로운 SAX 파서 인스턴스를 만드는 것을 알 수 있다.
아래 그림 10처럼 하나의 파서 인스턴스를 만들고 모든 xml 파일을 파싱하는데에 그것을 재사용하도록 코드를 수정하자.
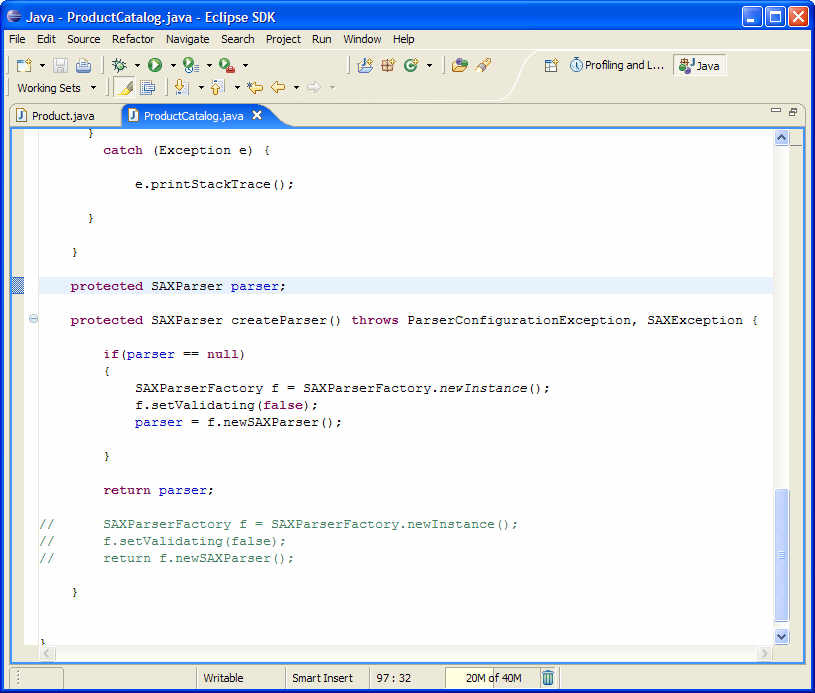
그림 10 소스 코드 수정
그림 10에서 보는 것 처럼 전역 SAXParser 인스턴스를 만들어서 성능 문제를 해결했다. createParser() 메소드는 파서를 초기화 하고 메소드가 호출될 때 마다 만들어진 인스턴스를 리턴한다.
다시 돌아가서 제품 카탈로그 어플리케이션을 다시 프로파일링 모드로 동작시켜 수정 내용을 검증해보자.
성능 문제 해결 검증하기
성능 문제 해결을 검증하기 위해, 위에서 말한 것 처럼 Product 클래스를 선택하고 우클릭해서 Profile As > Java Application를 선택한다.
프로파일링 옵션 마법사는 나타나지 않을 것이다. 이전에 설정한 프로파일링 옵션이 어플리케이션 실행시에 사용된다. 어플리케이션을 실행한 후에 실행 통계(Execution Statistics) 뷰를 열고 실행 시간을 비교해보자.
그림 11에 수정된 코드를 적용한 후의 실행 시간이 있다:
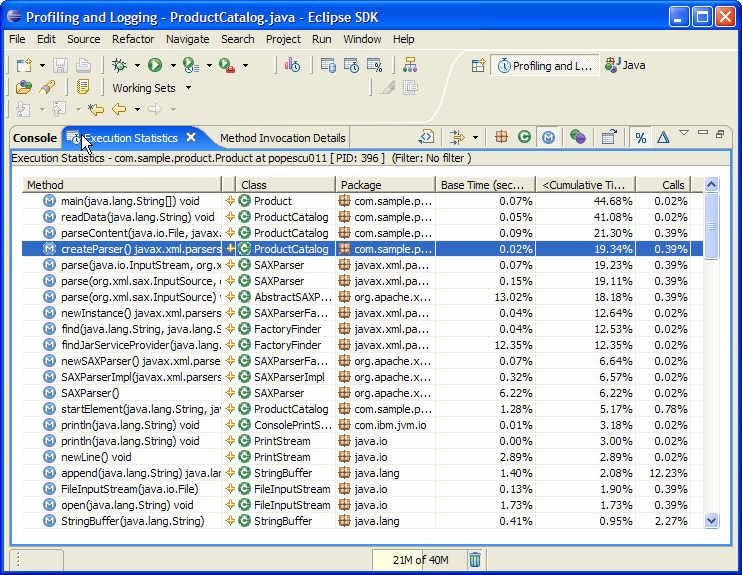
그림 11 실행 통계(Execution Statistics) 뷰
위 그림에서 보는 것처럼, 수정하기 이전에 거의 43% 였던 createParser() 메소드의 실행 시간이 단지 19%로 줄었다.
이 성능 향상은 파싱해야될 xml 파일이 많을수록 더 커질 것이다. 따라서 카탈로그에 추가되는 제품 정보 파일이 많아질수록 어플리케이션의 실행 시간이 엄청나게 줄어들게 될 것 이다.
결론
이 문서에서는 TPTP 프로파일링 툴을 사용해서 성능 문제를 확인하고 해결하는 방법을 설명했다. 이 문서에서는 다루지 못한 TPTP 툴의 많은 기능이 더 있다. 만약 이 툴의 기능을 더 알고 싶다면 여기에 있는 튜토리얼 슬라이드와 사용자 가이드들을 보기 바란다.
예제 실행하기
"ProductCatalog_example.zip" 파일에는 이 문서에 나와있는 예제의 소스 코드를 포함하고 있다. 이클립스의 “plugins” 디렉토리에 ZIP 파일을 풀면된다. 또한 제품 xml 파일들은 products.zip 파일에 있다. products.zip 파일을 시스템의 원하는 곳에 풀어놓고, 그 경로를 제품 카탈로그 어플리케이션의 프로그램 인자로 적어주면 된다.
Java and all Java-based trademarks and logos are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States, other countries, or both.



